
Project information
- Category: AI Modeling and Prediction
- Language: Python
- Project date: October, 2021
-
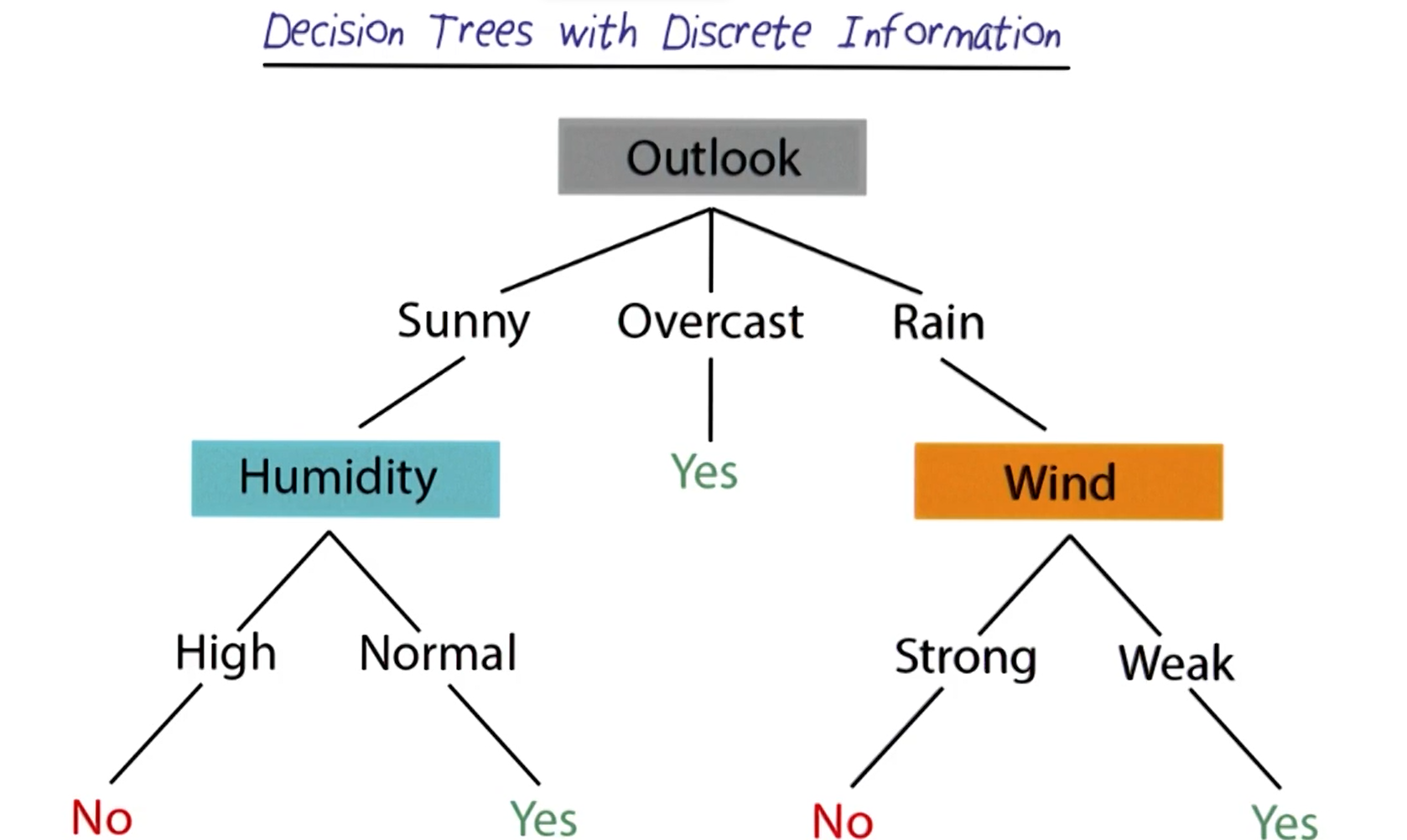
Video & Image 1 Source:
Georgia Tech OMSCS - Artificial Intelligence Course
https://omscs.gatech.edu/cs-6601-artificial-intelligence -
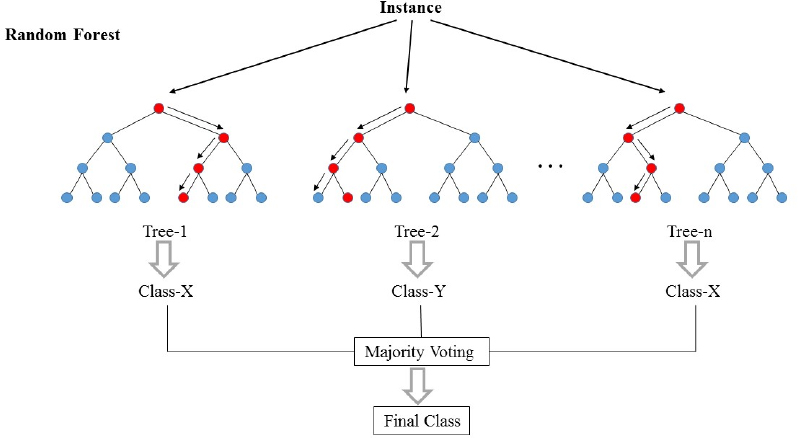
Image 2 Source:
Analytics Vidhya
Decision Trees & Random Forests
The goal of this project was to build, train and test decision tree models to perform multi-class classification. The trees were trained on the entire dataset, using k-fold cross validation (illustrated on Slide 1), to ensure all data contributed to the training. Each tree was created by randomly selecting a subset of the provided data and then randomly selecting attributes of that data to learn from. Gini impurity and information gain metrics were calculated and used to recursively build the initial decision trees, maximizing the purity of the division of the data. Finally, a collection of these decision trees was used to generate data outcome predictions, which were then averaged to produce a single prediction. Ultimately, my program was able to generate predictions with over 77% accuracy. Vectorization, by use of the Numpy library, was used throughout the program while working with the data to improve program efficiency.